Machine Learning Operations (MLOps) has come to be an important push for enterprises in 2021 and beyond – and there are clear reasons why this paradigm shift in Enterprise AI is upon us. Most enterprises who have begun data science and machine learning programs over the last several years have had difficulties putting even their promising machine learning models and proof of concept exercises into action, by deploying them meaningfully in production environments. I use the term “meaningfully” here, because the nuances around deployment make all the difference and form the soul of the subject matter around MLOps. In this post, I wish to discuss what ails enterprise AI today, sources of the gaps between production and proof-of-concept, expectations from MLOps implementations and the current state of the discourse on MLOps.
Note and Acknowledgement: I have also discussed several ideas and patterns I've seen from experiences I've had in the industry, not necessarily in one company or job, but going back all the way to projects and programs I've been in over the last seven to ten years. I don't mention clients or employers here as a matter of principle, but I would like to acknowledge mentors and clients for their time and energy and occasionally their guidance as well, in the synthesis of some of these ideas. It is a more boundaryless world than before, and great conversations are to be had regardless of one's location. I find a lot of the content and conversations regarding data science on Twitter and LinkedIn quite illuminating - and together with work and clients, the twain have constituted a great environment in which to discuss and develop ideas.
What ails Enterprise AI today?
Surely, with the large scale data pipelines companies have access to, the low cost of cloud native solutions, and the high level frameworks for building machine learning models, things should have become easier? Enterprises still seem to be failing in their efforts to build AI programs for many reasons despite these upsides. For one thing, building models has become easier than before. It takes less time to take (good enough or clean enough) data and build prototype models with this data. Regardless of how many hypotheses you have as a business leader or data scientist, you’re more likely in 2021 to be able to collect data and build prototype models with this data, than you were able to in previous years. In the past, you may have had to go through several organizational hoops to get your data, and then prepare this data and then build models. All of these processes have become a bit simpler in 2021, thanks to enterprise data stores maturing, frameworks for building ML models become better known, and greater numbers of data scientists being available to build models. While things are still quite complex for the uninitiated, those on the growth curve in data science have found this phase to be adding productivity to their prototyping efforts.
What hasn’t changed, though, is the process of taking these models to production. The model is largely seen as a software asset, and productionization of the model has been seen in this limited context. As we will discuss, it is important to challenge this mindset if we’re to build effective machine learning systems for production. The gap, therefore, between proof-of-concept models like we’ve discussed above, and production scale implementations of such models, is large. Real world implementations are more complex and tedious, and often, the hypotheses we want to build models for are a bit more well defined – this necessitates extensive data processing, profiling and monitoring. But the complexity doesn’t end there, even though there has been an effort on the part of MLOps practitioners to build end-to-end pipelines. You’ll note that none of these are ground-breaking realizations. MLOps is a practical field, thus far, intended to make all these models work for enterprises – but as we will see below, the practical nature of this field encompasses a number of domain, statistical, cultural, architectural and other considerations.
I wish to suggest before diving deeper into this post, that this trend towards MLOps adoption represents a noteworthy change in how enterprises see ML system architecture in 2021, as opposed to the previous decade. In a manner of thinking, represents a move towards the “plateau of productivity” in enterprise machine learning.

Domain Considerations Matter in Data Science, Data Engineering and MLOps
I wrote several years ago on this blog that domain knowledge is an important element in doing data science. Back then, as a data science neophyte learning from early experience in pure data science roles, I had made several observations about the impact of domain understanding on how quickly we can arrive at hypotheses for formulating data/AI problems. Looking back, this was an important lesson, because I now acknowledge the importance of domain knowledge every time I work on a data science project, or each time that I enable a data science team to be successful. Whether this is my own domain knowledge or that of SMEs, I am grateful for it, because without it, we could build anything, and it wouldn’t ultimately matter to anyone. Domain knowledge gives purpose to data and AI efforts. Without speaking to the domain experts and SMEs in various projects (finance, manufacturing, retail, energy and other industries), there would be little to no chance of timely and cost-effective success in characterising, ideating about and solving these problems.
It may not be immediately evident, however, that domain considerations matter in MLOps (and DataOps). Without an understanding of data generating processes, data formats, sources, rates, types, and data organization patterns, data fields, tables and even some of the process characteristics, we cannot understand data generation or transformation processes in enterprise data pipelines. We can also not understand how models are to be implemented, and what deployment means in different enterprise or customer contexts. When building and architecting machine learning systems, we end up needing to discover these details if we haven’t already. MLOps therefore cannot be ideated about in a vacuum, without consideration to the domain of the problem, or without consideration to the unique challenges of deploying models that domain. MLOps in logistics and supply chain problems, therefore, will be quite different from MLOps in manufacturing, retail or banking domains.
For instance, if we were building a classification model to sort defective parts from good ones on a manufacturing shop floor, we may need a real-time deployment system, with consideration to latency, edge based deployments of models, opportunities to inspect models as downstream processes or metrics may indicate process failure modes, and so forth. These considerations may not exist if we were building a system for enhancing ad revenue in a platform software company. The considerations there around uplift from pushing ads to new customers may require edge based deployments of a different kind, or federated learning needs, that may be unnecessary in the manufacturing example we discussed. To use an analogy, deployments are like different flavours of ice-cream, each requiring a different kind of appreciation. A failure to realize this may lead to difficulties in enterprises that may inadvertently underestimate the complexity of MLOps, of their own domain processes, or both.
Simplistic, Linear Pipelines Don’t Get Us Over the Line
The current thinking around MLOps is somewhat simplistic and linear, and I mean this in a specific way. There is a lot of discussion around data workflows and pipelines, metadata generation and management, and the metrics around model training and model performance. These are discussions around the management, transformation and profiling of data. Datasets are important to MLOps pipelines, and inasmuch as agility in data science is concerned, I’d even say that they are primary.
However, this notion of thinking only about the software and application-level implications of models and their deployment doesn’t address some of the needs from MLOps pipelines for enterprises. Notably, model interpretability and explainability, managing a diversity of deployment patterns (edge, batch, real-time or near-real-time), and the need to build repeatable pipelines or reproduce results. These problems cannot be broken down into just software applications, and require statistical rigour and attention to changing domain patterns. In fact, there is sometimes a desire on the part of ML engineering or MLOps practitioners to see these more statistical needs of MLOps as “not software engineering” and perhaps therefore “not easy to build for” – both of which may not be true, especially as the space of tools and implementations of statistical models for interpretability/explainability expands just as ML implementations have expanded.
Imagine that you have built an MLOps pipeline to build a dataset for a specific use case, and deployed it and the model eventually, and all’s well. If there’s a need for a new use case, you’re likely to begin back at square one, and build new pipelines, especially if you don’t have a clear and unified data model. As we will discuss in a later section on architecture, this is important to consider in ML engineering – more than one use case may require your data pipeline. This also means that simplistic and linear pipelines can only serve a limited purpose when you’re required to build many such pipelines across enterprise workloads.
For instance, it is possible to build SHAP scores for models given a specific dataset, and for companies with regulatory needs, there may be a reason to deeply analyze and publish results such as these. Therefore, MLOps shouldn’t only be about building simplistic DAGs or workflows in your YAML engineering tool of choice, or building and deploying metadata-tracked machine learning training/inference workflows. These are necessary, but insufficient for good MLOps implementations – chiefly because there are many other statistical and probabilistic considerations around MLOps which also deserve attention.
Data Architecture Before MLOps, but Business Needs First
There was an interesting discussion here recently around the theme of “Data before models, but problem formulation first”. The interesting article in question describes the specific challenges of thinking about data science problems based on business problems, and being “data-driven” in thinking about and building models for our hypotheses. I posit that a similar paradigm applies to MLOps. Data architecture understandably matters a great deal for success MLOps implementations, because it encompasses very foundational organizational processes and needs around data collection, storage and management, governance, security and quality, access patterns, ETL/ELT, sandboxes for analytics, connections to BI and reporting systems, and so on. Ultimately, this complex web of processes and technologies (because data architecture is more than just storing and retrieving data) is meant to perform some function of the business. As W. Edwards Deming said, “Data are not collected for museum purposes” – they are collected for a decision to be made, or for some end use. In the world of MLOps, we enable such decisions to take place on top of the data provided to us through an enterprise data architecture such as this one described above.
While typical enterprise data architectures are driven by the capabilities of tools and cloud scale applications more and more (because of the economies of scale of cloud providers, and the low barriers to entry), there is an important set of decisions every enterprise data architect has to answer for, around the specific needs of the organization, and how the architecture in question enables that to happen. Seemingly trivial decisions taken at the design phase of a data lake or data warehouse can have long lasting implications for the delivery of value from analytics, machine learning and MLOps. Data architecture is certainly important for MLOps, but the more fundamental needs of the organization – the kind of data required, the strategic importance of it, the decisions that need to be made across use cases, security and access patterns for data analysis and data science, and many more operational aspects of data – all of these are important and have a bearing on MLOps effectiveness too. So if you’re a data scientist or MLOps practitioner looking to improve your impact and effectiveness in solving problems, understand the underlying data architecture more deeply first. Sometimes, doing this can be hard – especially if there are no stakeholders who can explain it well – but this kind of fundamental understanding and context are highly underrated and have an outsize impact on the success of data science and ML programs eventually.
The Enterprise Model Sanctuary: Many Simpler Models, A Few Complex Models, and Other Combinations
A cursory glance at machine learning and MLOps forums, discussions and content indicate that the thinking around model development techniques is method centric, and not business centric. A large number of the discussions are a consequence of what’s required for companies at scale innovating on a few complex models with huge amounts of data – and these are legitimate and interesting discussions for sure. For example, most MLOps discussions I have come across seem to discuss the deployment of deep learning models. They discuss text and unstructured data processing, and complex image processing pipelines. Whether the use of tools like Kubeflow for training and deploying models in a distributed fashion, or the use of MLFlow for tracking metrics and performance, these are all legitimate considerations that may solve subsets of the ML deployment space. However, machine learning state-of-the-art is rarely required for enterprises looking to get value out of their specific use cases. The large majority of use cases in the industry are for simpler models, though and this is why simpler pipelines could do a large part of the value creation. I say this from experience and with confidence, having seen numerous projects where managers struggle to make sense of ML outcomes for their business, but have less difficulty making sense of data aggregations, summaries and statistics based on the data. The enterprise model ecosystem is more likely to resemble a zoo or even more accurately a sanctuary of different models, where each model may have its own specific needs and requirements.
Model development in mature organizations generally is an afterthought to carefully evaluating data and the evidential findings from it on merit, and then exploring hypotheses subsequently. Enterprises at lower levels of maturity have difficulty getting value from such an approach, however, and many leaders there may still rely on dashboards and reports. Clearly, there is an important and untapped market in business intelligence from big data. There is also a huge market for implementing simpler models based on clearly defined hypotheses. In many cases, enterprises may need many such simpler models, one for each stratified part of a specific use case. For instance, if you’re a market research firm estimating sales in a market segment, you may wish to build many such models for each sub-segment. If you are an equipment manufacturer doing quality checks using machine learning models, you may wish to use attribute based classification models, one for each product line, and perhaps you want to build many of them. The true value of MLOps in these cases is not in managing the complexity of deployment for one complex model, but in enabling many simpler models to be taken to production quickly and efficiently. These simpler models may then provide a baseline with which to build more complex models as needed.
Machine Learning Systems are Stochastic, Not Deterministic
Perhaps I’m stating the obvious, but it needs to be said. The underlying nature of data generating processes and machine learning models is stochastic and not deterministic. Whether we’re talking about manufacturing process metrics, banking and finance transaction data, energy sector data around load, power, usage, and so forth – all of these data are generated from stochastic data generating processes, even if they come from engineered systems. Machine learning models are also never exact mathematical formulations – they are almost always stochastic processes. There is a little to unpack here, so I’ll get into a few instances. What this stochasticity means, is that machine learning models exhibit variability in results from situation to situation, and that this will be quite evident in production. In order to begin building machine learning systems, we need to perform exploratory data analysis prior to training time, prepare features for our hypothesis, check assumptions based on the feature and the model formulation, and then build models and evaluate them. What it also means, is that we need to build safeguards to ensure that these assumptions are valid when doing production scale inference. It means that we may have to reformulate problems, as the underlying conditions of the data generating process changes. In case of deep learning models, sophisticated tensor transformations and training loops are required as part of the normal training loop of deep learning models.
When the model is eventually trained to the required level of performance and rendered, they too represent a solution at a specific point in time. MLOps is not about “train once, deploy everywhere”, but about “routine retraining and redeployment”. This makes ModelOps and the continuous training lifecycle of model development as important a consideration in MLOps as DataOps is. A lot of discussion around MLOps today is centered around data preparation – and the motivation for this, of course, is the fact that there are significant data preparation challenges that data scientists face. However, model training in the real world cannot be wished away by despite the prevalence of AutoML, although AutoML tools are one path for progress. As of 2021, for most use cases, model definition and training is still done manually, even if tuning and optimizing the model are automated. In MLOps lingo, we are referring to the importance of using feature stores, and their impact on data drift and concept drift analysis. While a healthy discussion is in progress on these topics, the instrumentation in actual implementations of data drift and concept drift identification and measurement tends to vary. Some tool chains are ready for this change, and others just aren’t.
More broadly, some MLOps implementations may account for these stochastic and probabilistic characteristics of ML systems, because their data scientists ask the hard questions after training and during/before deployment. On the other hand, it is likely that most MLOps implementations today treat models merely as pieces of software. The latter pattern leads to the unfolding of technical debt of various kinds later in the lifecycle of the system. This technical debt currently represents building additional regulatory checks, doing interpretability analysis, meta-data logging, model performance metrics, and so on – and over time, this set of secondary considerations may grow much bigger.
Changing Skillsets and Roles for MLOps
Companies looking to hire top ML talent as of 2021 are pushing for a greater number of high quality data engineers with MLOps skill sets. This is in contrast to emphasis on data science hiring in the past. Hiring pipelines for data and AI roles (I’ve seen a few different ones over the last few years) tend to emphasize programming, statistics, databases and specific technologies for data science – of late, this is largely SQL, Python, with a smattering of distributed frameworks and tools, and skill sets in deep learning, tabular data analysis and the associated frameworks and tools for solving problems in this space. For data engineering roles, over the years I’ve seen skill requirements specifying systems programming and strongly typed languages such as Java and Scala, experience working on JVM languages, in addition to SQL, databases, and a lot of the back-end software engineering skill sets we see for application developers elsewhere. For data engineers working on big data technologies, there’s very often a need to be familiar with NoSQL databases, or graph databases, depending on the role and use cases, in addition to the Hadoop-and-friends ecosystem, and cloud engineering skills such as AWS or Azure. While the data scientist’s role and skill set has come to include domain considerations, advanced statistical and ML models, cloud-native and large scale data science and deep learning and communication/presentation of data and insights, the data engineer’s role has become broader around systems engineering and design.
Someone said (in fact, in this talk) that data engineers ought to build frameworks, and not pipelines – and this is a fair assessment of how to use this broad and useful skill set in data engineering. There has been a healthy discussion in various forums, talks and the like on ML engineering roles which combine elements of these two different skill sets. All of these conversations around skill sets are important context for where we’re heading in data science and engineering space overall too. MLOps, unlike DevOps before it, should not be constrained by the limited value addition possible outside of data scientist or data engineering roles (the bulk of DevOps roles are administrative in nature). They cannot be construed as or see themselves as configuration file engineers, for lack of a better term. In fact, their role could be much broader – as systems engineers spanning a range of capabilities in both data science and data engineering, while not possessing expertise in any one of these (themselves diverse) areas. MLOps roles should perhaps also emphasize domain knowledge or expertise of some kind – since ultimately, the outcomes here are practical and related to business value from ML. There are many outcomes and opportunities for talent and skill sets for sure, but these stand out as being relevant. What is for sure is that the data scientist’s role has changed (as has the data engineer’s), and the old and unyielding challenges being faced by data scientists are taking on new definitions and manifestations – thereby requiring new mindsets, new skill sets, and new processes to come forth.
In my view this churn in the extant data science and engineering role paradigm is a welcome development because enterprises first want to realize value from DataOps and MLOps simultaneously today. As we will discuss later in this post, while models are important, business managers will continue to derive value from analytics and reports – and perhaps there has never been a better time to build on that need than 2021. Also, the emphasis on data engineering roles as on date is well-founded. From practical experience as a data scientist who worked on a range of problems from relatively simple ML to complex deep learning models, I will happily acknowledge that data engineers I have worked with were indispensable to the success of the projects I succeeded on. However, leaders hiring for ML roles should not think that the role of the data scientist is no longer required. I believe this emphasis on data engineering is a passing trend as enterprises build foundational pieces that enable value from data. The focus will therefore shift once again to business value from data, and that this automatically means that statistical, data science and ML skills will continue to be in vogue through this shift and afterwards.
Don’t Ignore Decision-Making Culture
Organizational culture matters a lot for the success of MLOps, as much as it does for any digital transformation program. MLOps represents, in a way, a desirable end-state or the happy marriage of data science and data engineering in a given enterprise and data architecture context. However, both data science and engineering can only be valuable and effective in organizations whose leaders think about and talk about data and use the data and insights from these data for taking decisions. The latter is a cultural synthesis, and not just a technology adoption process or workflow that one can execute on demand. Being a cultural matter, it has to do with behavioural and attitudinal patterns that ultimately enable data and insights to be used for decision making.
The adoption of data driven decision making represents a shift from thinking about business processes, systems and decisions in terms of rules (“Rules are for lazy managers”, to paraphrase Simon Sinek), to an open-minded thought process around data and AI systems. When leaders stop thinking in terms of rules, and start thinking in terms of systems, they are often imagining situations of change, synthesis, formation and deformation of patterns, structures and interactions. They begin to see their role as an influencer more and as a commander less, and this shift in thinking can enable them to make subtle changes to their managerial approach, driven by data.
In the earlier post I wrote about OODA, and the AI-enabled generalist, there is a point I make about the decision making language of organizations. This kind of development of a decision making language requires a way of thinking about the enterprise’s systems, processes, and also the ML models in new ways. It requires an openness of mind in decision making to adopt models as thinking tools. In a sense, the modern AI-empowered generalist could be seen as a prototype for a supreme pragmatist. Enterprises want rational actors at their helm, at least for the functions that require data driven decision making – and such rational actors can be groomed in a culture that doesn’t shy away from challenging the current rules and norms on decision making, and is willing to look at data and models.
Data/AI Exponents as SMEs and Future Leaders
Organizations come to embrace data, ML or even MLOps so that they can ultimately derive value from data, and this cannot be done without talent that unlocks value from data. Be this talent data science talent or data engineering/architecture talent, there is both a topical / functional need and a strategic value of these roles in enterprises, and this tends to be overlooked in data strategy. This is because of the value such individuals accumulate over time, as they build data pipelines and AI/ML models, accumulating a lot of knowledge about business processes, customers and also domain knowledge in the process. When you have a data scientist in your team who has built a few different models that explain different elements of your business, processes or customer behaviour, they become invaluable assets for both developing further models, and for analyzing customer or business or process behaviour. Such individuals can also become effective leaders and transition to process management roles.
MLOps and DataOps engineers in an organization can therefore themselves be considered Data/AI SME roles – and this is an important source of value that is often overlooked in organizations. A lot of organizations still see data/AI resources as just means to an end, but in fact, many of these roles can become storehouses of domain knowledge. MLOps can potentially enable the tacit knowledge from such individuals to be effectively captured for process management as well – this may be an important opportunity for value creation from MLOps. MLOps can also accelerate the development of data-driven leadership talent. When exposed to the models used to take decisions, and the specific mechanisms of taking such decisions, leadership potential for process leadership is improved.
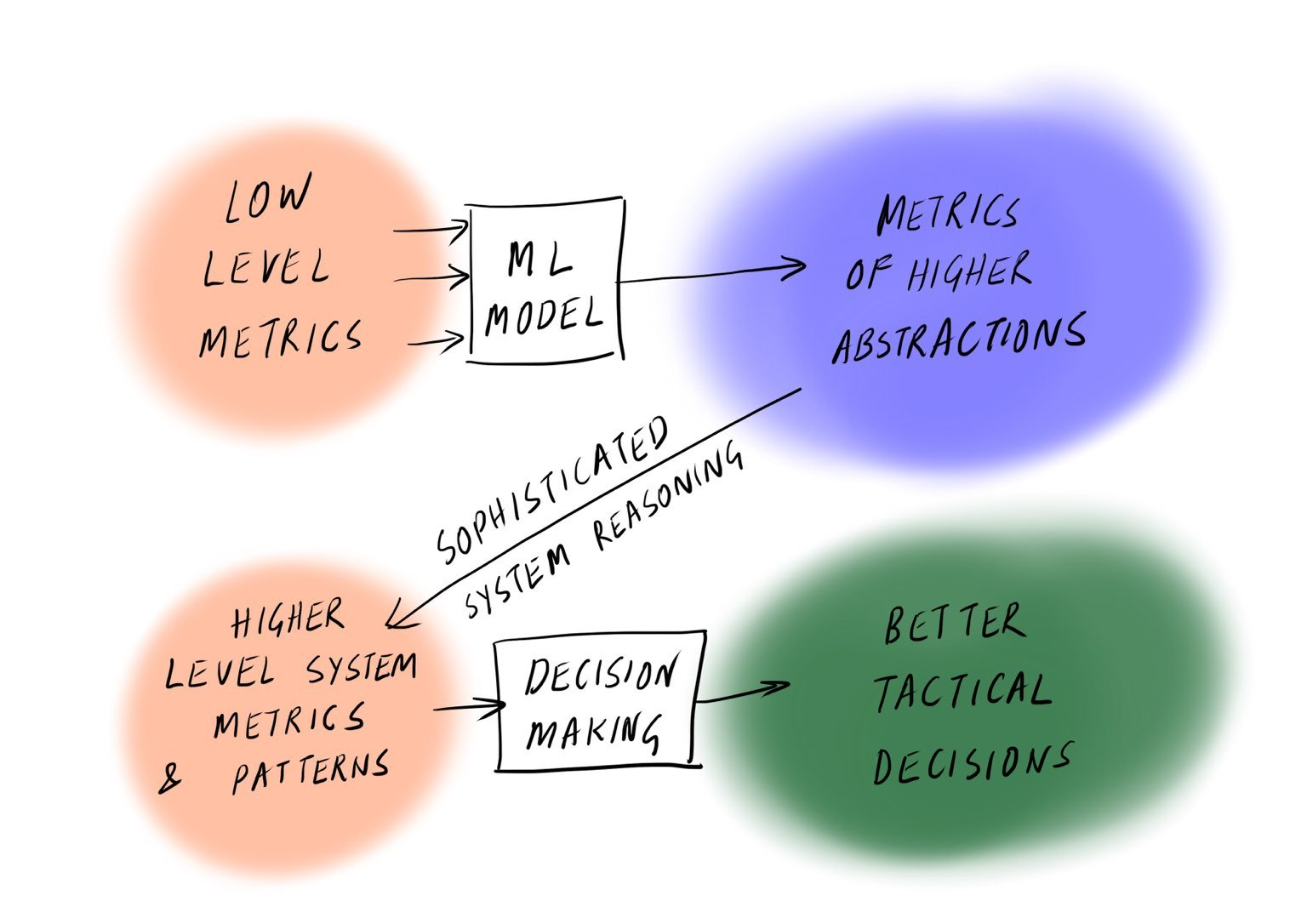
In an earlier post, I discussed the importance of higher-level decision making languages, the OODA decision making loop, and how AI can enable a new generation of generalists. I would suggest that this is a useful idea to consider in the broader context of building a data-driven decision making culture.
“Data Before Models” also implies “Models After Data”
The purpose of this heading is to draw attention to the fact that the best data pipelines won’t help, if we aren’t doing much with the data we prepare. We have to eventually build models with this data of one or other kind for actually taking decisions. Many recent discussions around MLOps talk about data-centric AI, and above, we have discussed data architecture and other elements of enterprise systems and culture that contribute to MLOps success. We have also discussed the stochastic nature of data generating processes and machine learning systems. There are important implications from the core ModelOps processes as well, and we will discuss them here, finally. The process of developing models, as I have discussed above, has become easier now than ever before, at least in software. The careful formulation and evaluation of model hypotheses, statistical analysis of the input data and features, and the checking of assumptions – these still remain harder, more tedious and less trivial, as they were before. This necessitates the importance of statistical analysis and exploratory data analysis. Without these foundational steps, ML models can be built with high bias or high variance, thereby setting up the use case for higher failure rates and lower effectiveness overall. This bears introspection and repetition, since there seem to be two schools of machine learning and data science professionals – there seems to be a group of professionals who believe strongly that mathematical and statistical thinking are important for doing data science. There’s another group of professionals and practitioners who think otherwise, that the software elements of data science modeling can be learnt by someone without knowledge of statistics or machine learning.
In my experience, the statistical analysis and EDA are fundamentally important for machine learning – they forms an integral and important part of extracting value from the data we have, and making sense of it, before we solve problems. A number of business situations require us to think in terms of data distributions and stochastic processes. To build things that scale within MLOps pipelines, some of us may need to have an open mind about exploring the mathematical underpinnings of things like gradient descent or batch normalization, or activation functions. This open-mindedness is important for a key reason – a lot of MLOps engineers being trained today may assume that the data science is easy, or trivial, because people who don’t know statistics are building models, or because they can, if they just follow a simple workflow. I know this to be patently untrue – if you want to develop a model worth anything in an enterprise, you may have to start from formulating and thinking about the business problem, get to the EDA and statistical analysis and built out tests for assumptions checking, and then experiment with different models. You have to get into the probability and statistical analysis eventually, or you will be forced to rediscover the effectiveness of these mathematical and scientific methods. Even if you manage to build one or a few models, there will be situations where you’re required to explain these models. Not only will ML engineers or data science engineers be more confident when they are able to reason about the mathematics of machine learning, but their ability to build and scale systems for the enterprise improves. Their ability to think about the implications of these models for different related use cases, for different deployment modes, different source data, and different data quality considerations also improves. By checking assumptions on the features, they could stave off big challenges that may arise when the model is implemented in production.
Statistical analysis and machine learning model development have been core and will be core to data science, regardless of the peripheral engineering required for realization of value. Data engineering and MLOps as allied fields help realize this value at enterprise scale. It is the process of data science and model development that ultimately converts data into insights – and insights are the primary purpose of investing in enterprise data and AI projects and programs in the first place. They will therefore continue to be a good bet for practitioners in future – as long as they realize that those skills alone cannot take them over the finish line.
Concluding Remarks
I hope that you’ve benefited by reading this rather lengthy post on MLOps and Enterprise AI. If anything, it allowed me to explore my own experiences, document a few patterns I see in the development of truly enterprise ready AI, MLOps toolchains and capabilities, and also explore sources of value from MLOps for enterprises. If you have questions or ideas, please leave a comment or tweet to me at @aiexplorations.
Further Reading/Listening
- Data Science is Different Now, by Vicki Boykis:
- Problem Formulation Comes First by Brian Kent on Crosstab.io
- Build Frameworks, Not Pipelines – a Data Engineering Talk on PyData
- From Model-Centric to Data-Centric AI – a discussion on Enterprise scale AI with Andrew Ng and others
- ML Engineering for Production – another discussion on ML for production with Andrew Ng and others

Leave a comment